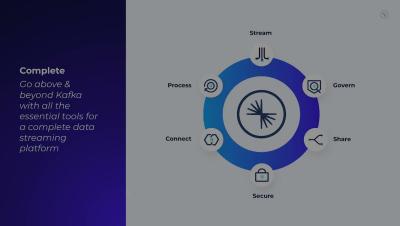
Learn the basics of Apache Flink® and how to get started with simple, serverless Flink! Flink is a powerful, battle-hardened stream processor that has rapidly grown in popularity, becoming the de facto standard for stream processing and a top-five Apache project. Kai Waehner, Field CTO at Confluent, explains how Flink fits into your data streaming architecture, why stream processing is needed for real-time data, and how Flink’s underlying architecture provides a number of advantages.