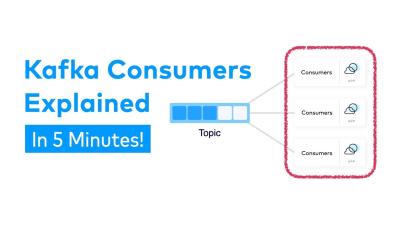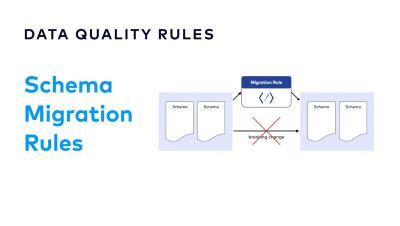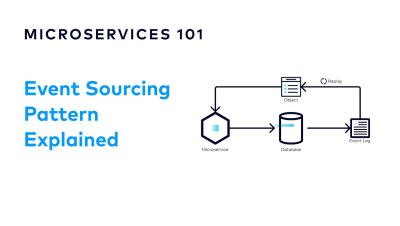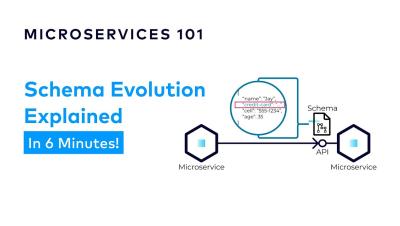
How to Evolve your Microservice Schemas | Designing Event-Driven Microservices
Schema evolution is the act of modifying the structure of the data in our application, without impacting clients. This can be a challenging problem. However, it gets easier if we start with a flexible data format and take steps to avoid unnecessary data coupling. When we find ourselves having to make breaking changes, we can always fall back to creating new versions of our APIs and events to accommodate those changes.