Iguazio Releases Version 2.8 Including Enterprise-Grade Automated Pipeline Management, Model Monitoring & Drift Detection
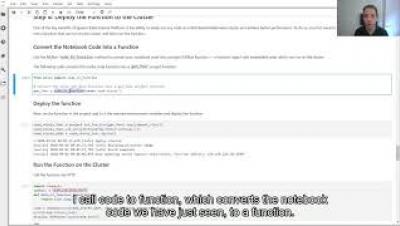
We’re delighted to announce the release of the Iguazio Data Science Platform version 2.8. The new version takes another leap forward in solving the operational challenge of deploying machine and deep learning applications in real business environments. It provides a robust set of tools to streamline MLOps and a new set of features that address diverse MLOps challenges.