What is the Listen to Yourself Pattern? | Designing Event-Driven Microservices
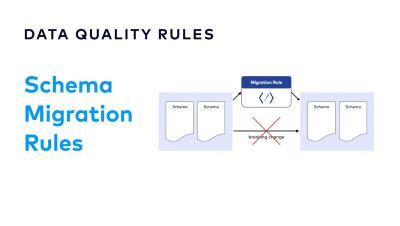
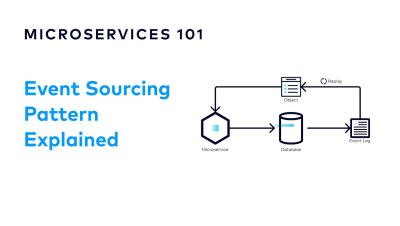
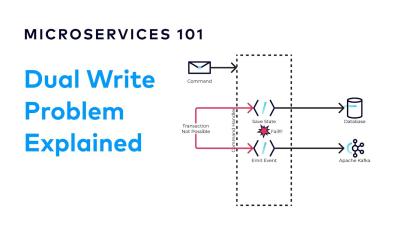
The Listen to Yourself pattern is implemented by having a microservice emit an event to a platform such as Apache Kafka, and then consuming its own events to perform internal updates. It can be used as a solution to the dual-write problem since it separates Kafka and database writes into different processes. However, it also provides added benefits because it allows microservices to respond quickly to requests by deferring processing to a later time.