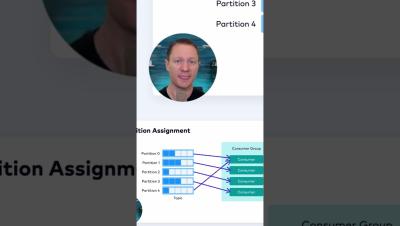
Introducing Confluent Cloud OpenSearch Sink Connector
Amazon OpenSearch is a popular fully managed analytics engine that makes it easier for customers to do interactive log analytics, real-time application monitoring, and semantic and keyword searches. It can also be used as a vector engine that helps organizations build and augment GenAI applications without managing infrastructure (we’ll talk about this in future blogs). Additionally, the service provides a reliable, scalable infrastructure designed to handle massive data volumes.