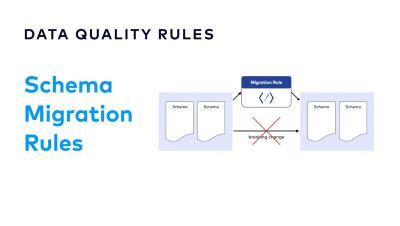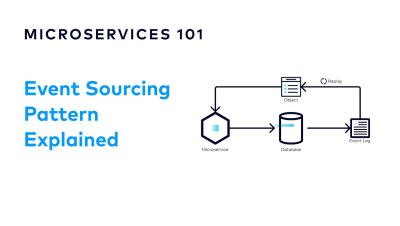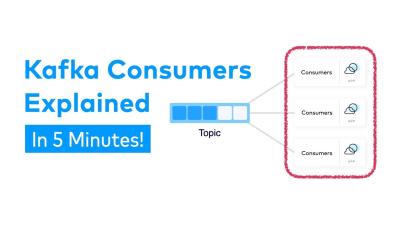
What is a Kafka Consumer and How does it work?
Now that your data is inside your Kafka cluster, how do you get it out? In this video, Dan Weston covers the basics of Kafka Consumers: what consumers are, how they get your data flowing, and best practices for configuring consumers in a real-time data streaming system. You will also learn about offsets, consumer groups, and partition assignment.