ThoughtSpot for Google Cloud Platform
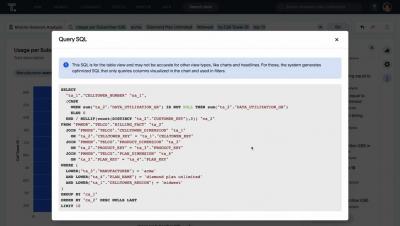
ThoughtSpot is partnering with Google Cloud to expand self-service analytics capabilities beyond the dashboards! Now you can use AI-powered search to query Google BigQuery in real-time, access the Looker semantic layer to obtain reliable and standardized data models, and close the productivity loop with ThoughtSpot plugins for Google Sheets, Connected Sheets, and Slides.