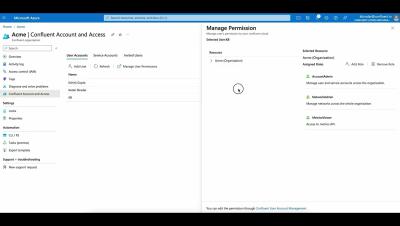
Confluent Access Management
Confluent Access Management, developed alongside Microsoft Azure, allows organization admins to add and manage users and user permissions after they are created via the Azure portal. See how it works.


Happy holidays from Confluent! It’s that time in the quarter again, when we get to share our latest and greatest features on Confluent Cloud. To start, we’re thrilled to share that Confluent ranked as a leader in The Forrester Wave™: Streaming Data Platforms, Q4 2023, and The Forrester Wave(™): Cloud Data Pipelines, Q4 2023! Forrester strongly endorsed Confluent’s vision to transform data streaming platforms from a “nice-to-have” to a must-have.
Imagine easily enriching data streams and building stream processing applications in the cloud, without worrying about capacity planning, infrastructure and runtime upgrades, or performance monitoring. That's where our serverless Apache Flink® service comes in, as announced at this year’s Current | The Next Generation of Kafka Summit.
Apache Kafka® has become the de-facto standard for streaming data, helping companies deliver exceptional customer experiences, automate operations, and become software. As companies increase their use of real-time data, we have seen the proliferation of Kafka clusters within many enterprises. Often, siloed application and infrastructure teams set up and manage new clusters to solve new use cases as they arise.
Today, we’re excited to announce the general availability of Data Portal on Confluent Cloud. Data Portal is built on top of Stream Governance, the industry’s only fully managed data governance suite for Apache Kafka® and data streaming. The developer-friendly, self-service UI provides an easy and curated way to find, understand, and enrich all of your data streams, enabling users across your organization to build and launch streaming applications faster.