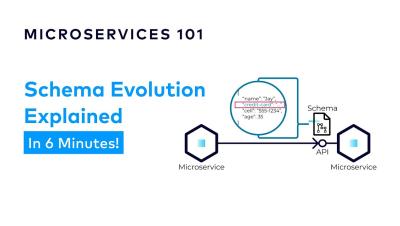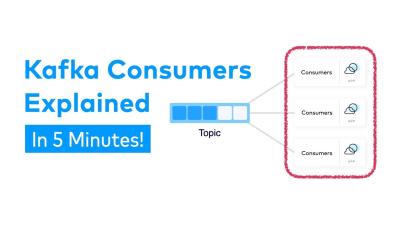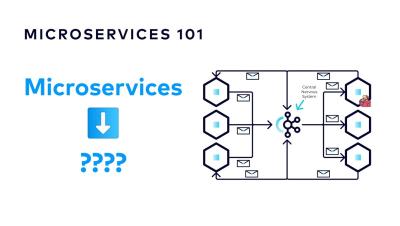
How to Unlock the Power of Event-Driven Architecture | Designing Event-Driven Microservices
An Event-Driven Architecture is more than just a set of microservices. Event Streams should represent the central nervous system, providing the bulk of communication between all components in the platform. Unfortunately, many projects stall long before they reach this point.