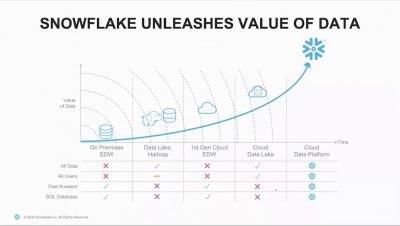
Factory Edge to Cloud Analytics- Three Fundamental Steps to Success
We recently Googled the manufacturing use case “predictive maintenance” and was astonished by the results there were 82 MILLION results returned. Next, we Googled “process optimization” and it yielded even more results – 302 MILLION. Clearly, these use cases are top of mind in today’s manufacturing landscape, considering digital transformation will deliver $11 Trillion USD in economic value by 2025.