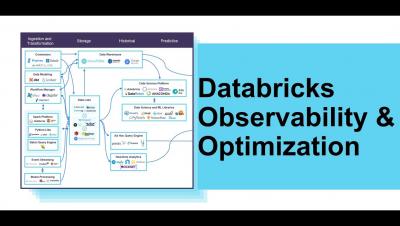
Unraveling AI Entrepreneurs #1
Do you have a billion dollar idea that you can solve using AI? Unraveling AI Entrepreneurs Tips is a new video series brought to you by Sandeep Uttamchandani, Unravel Data Chief Product Officer, for engineers and product managers. Learn More About Unravel Data