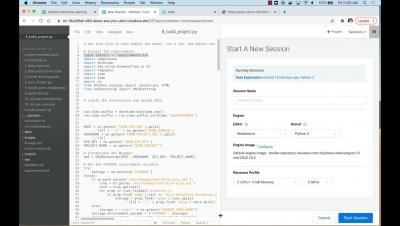
Managing Python dependencies for Spark workloads in Cloudera Data Engineering
Apache Spark is now widely used in many enterprises for building high-performance ETL and Machine Learning pipelines. If the users are already familiar with Python then PySpark provides a python API for using Apache Spark. When users work with PySpark they often use existing python and/or custom Python packages in their program to extend and complement Apache Spark’s functionality. Apache Spark provides several options to manage these dependencies.