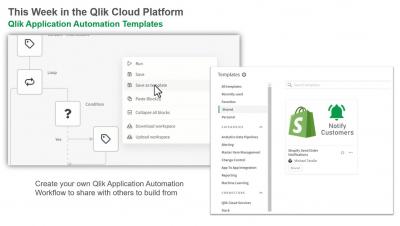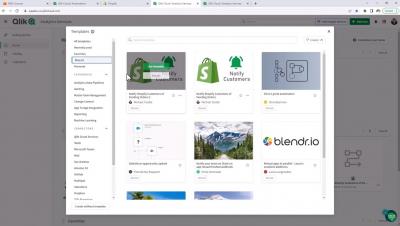
Create and Share your own Qlik Application Automation Templates
You can now save your Qlik Application Automation workflows as templates to share with others. Jump to 04:20 to see how it is done.


Qlik has performed extremely well in peer-based reviews over the years, but one peer-based review organization which sometimes flies under the radar is G2. They shouldn’t - G2 has been around for a decade and published over 1.7 million reviews covering thousands of software products.