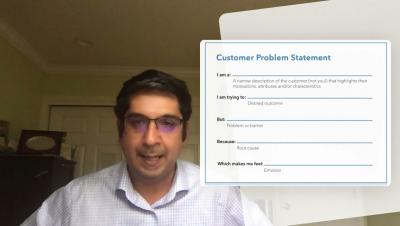
Data Chief Live: External data: Your secret weapon in a cookie-less world
How do you get to know your customer in a cookie-less world? Join Rosemary Hua, Global Head of Retail & CPG GTM at Snowflake and Forbes 30 Under 30, Erik Mitchell, founder and principal at Seek Data, Nik Lampropoulos, Global Director of Data, Insights & Analytics, Hogarth Worldwide and Cindi Howson, ThoughtSpot CDSO, as they discuss questions like.