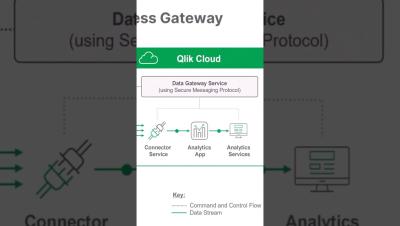
Last year, we introduced Freight clusters, a new, cost-effective Confluent Cloud cluster type—purpose-built for high-throughput, latency-insensitive workloads—such as observability data, batch pipelines, and AI/ML data ingestion. Since then we've been working with early access customers to take their workloads to production, and in doing so, have helped them achieve 90% lower infrastructure costs, while maintaining the reliability we all know and expect from Confluent Cloud.