

Modernizing the Analytics Data Pipeline
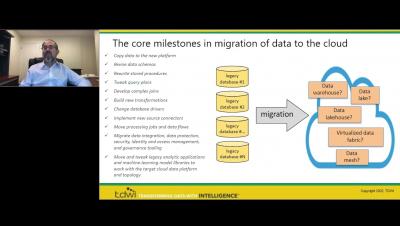
Enterprises run on a steady flow of best-fit data analytics. Robust processes ensure these assets are always accurate, relevant, and fit for purpose. Increasingly, organizations are implementing these processes within structured development and operationalization “pipelines.” Typically, analytics data pipelines include data engineering functions such as extract-transform-load (ETL) and data science processes such as machine-learning model development.








